Go 1.25 Introduces Experimental Green Tea Garbage Collector
The Green Tea Garbage Collector
Go 1.25 has introduced an experimental garbage collection mechanism that goes by the name of Green Tea. If you're developing applications in Go, you'll want to pay attention. By setting GOEXPERIMENT=greenteagc during the build process, you can access this new collector, which has shown promising benchmarks: many workloads report a streaming reduction of about 10% in garbage collection time, with some impressive scenarios even hitting a 40% decrease!
With Green Tea deemed production-ready and already in use at Google, this isn’t just a fleeting experiment. It's a substantial enhancement to Go's memory management that developers should consider trying. However, caution is warranted: not all workloads will experience benefits, and in some cases, you might not see any improvement at all. Your feedback will be pivotal as we assess its viability for future implementations—the goal is to make this the default garbage collection method in Go 1.26.
If you encounter any issues or observe notable successes while using Green Tea, we highly encourage you to share your experiences. You can report your findings by filing a new issue for problems or adding your insights to the existing Green Tea issue.
This blog post draws upon insights from Michael Knyszek’s talk at GopherCon 2025, setting the stage for a deeper understanding of garbage collection in Go.
Tracing Garbage Collection
Before we dive deeper into the workings of Green Tea, let’s clarify what garbage collection entails in general and its implications for Go programming.
Understanding Objects and Pointers
The primary goal of garbage collection is to automatically reclaim memory that a program no longer requires. In Go, the garbage collector focuses on objects—the chunks of memory representing Go values—and pointers, which are essentially indicators of where those objects reside in memory.
Let’s get a bit technical. Objects are created in the heap when the Go compiler determines that dynamic memory allocation is necessary. For example, when you create a slice of pointers like this:
var x = make([]*int, 10) // global
Here, the memory for x has to reside on the heap because the compiler can't predict how long it will be used.
Pointers serve as references to these memory locations. To illustrate, you might obtain the pointer to the first element in the previously allocated slice using:
&x[0] // 0xc000104000
The Mark-Sweep Algorithm Explained
The approach Go uses for garbage collection is often termed tracing garbage collection. The idea is simple: the garbage collector "traces" the pointers in the program to ascertain which objects are still in use. Specifically, Go employs the mark-sweep algorithm, which, despite being a mouthful, operates on a rather straightforward principle.
To visualize this method, think of your heap memory as a graph where objects are nodes and pointers are the edges connecting them. The process unfolds in two phases.
First, during the mark phase, the garbage collector traverses this graph starting from designated points known as roots, which include global and local variables. It systematically marks every visited object to prevent cycles.
This marks the beginning of the mark-sweep process. In the subsequent sweep phase, the collector identifies objects that weren’t marked during this traversal—these are the unreachable ones. With Go's semantic guarantees, these unreachable objects can be safely cleaned. The algorithm then frees the memory occupied by these unvisited nodes, making room for future allocations.
But Is It Really That Simple?
You might think this is an oversimplification, and you’d have a point. Garbage collection tends to be seen as something akin to magic, and while the essence is captured here, there are intricacies involved. For instance, this algorithm runs concurrently with the application code, which creates hurdles particularly when dealing with a mutating graph. Additionally, the algorithm employs parallelization, an aspect we’ll revisit later.
In a nutshell, while garbage collection in Go may seem complex, the core mechanism resembles a fundamental graph traversal operation.
Illustrating the Graph Flood
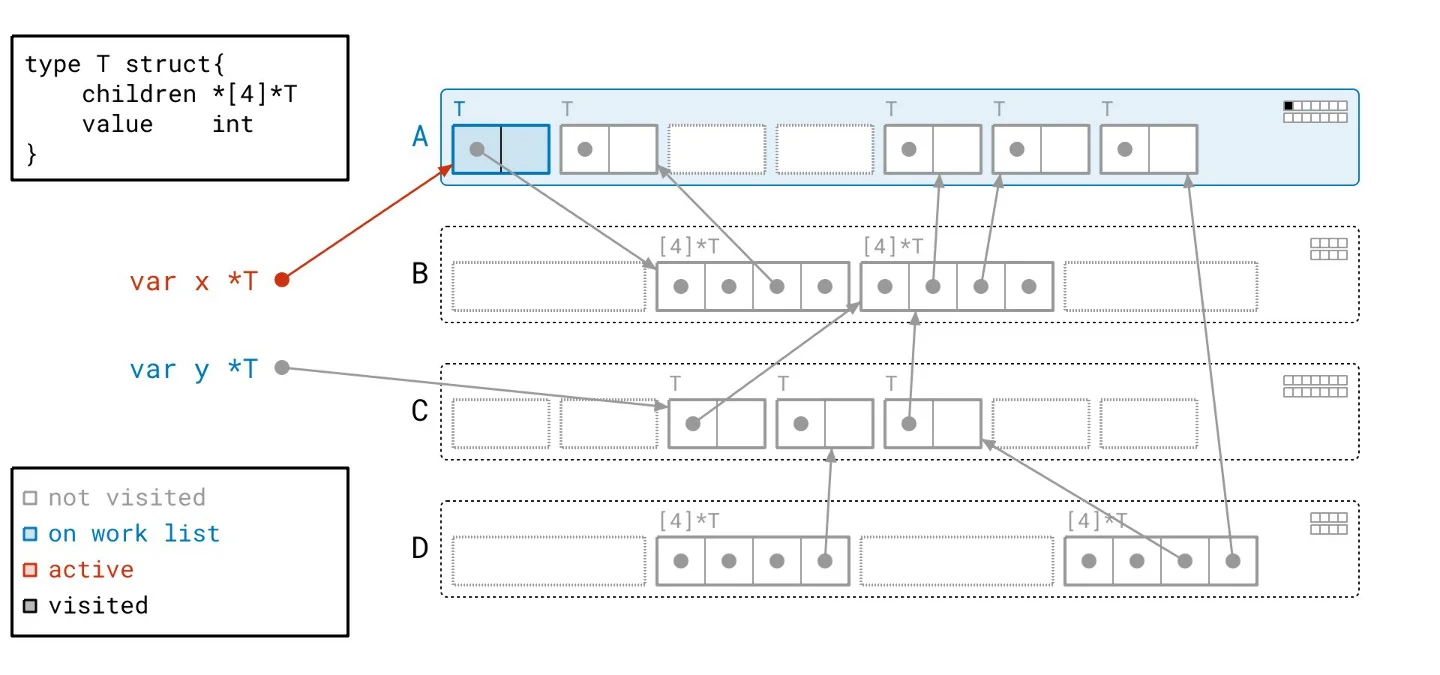
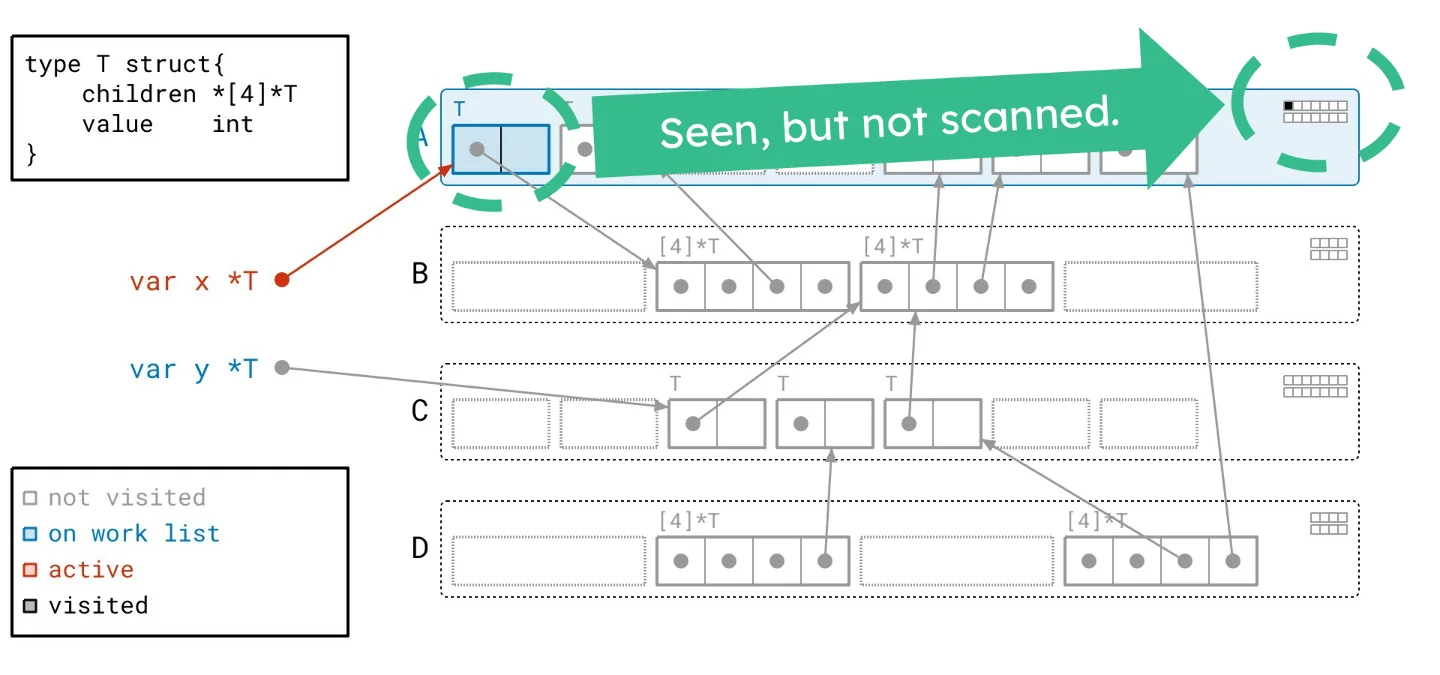
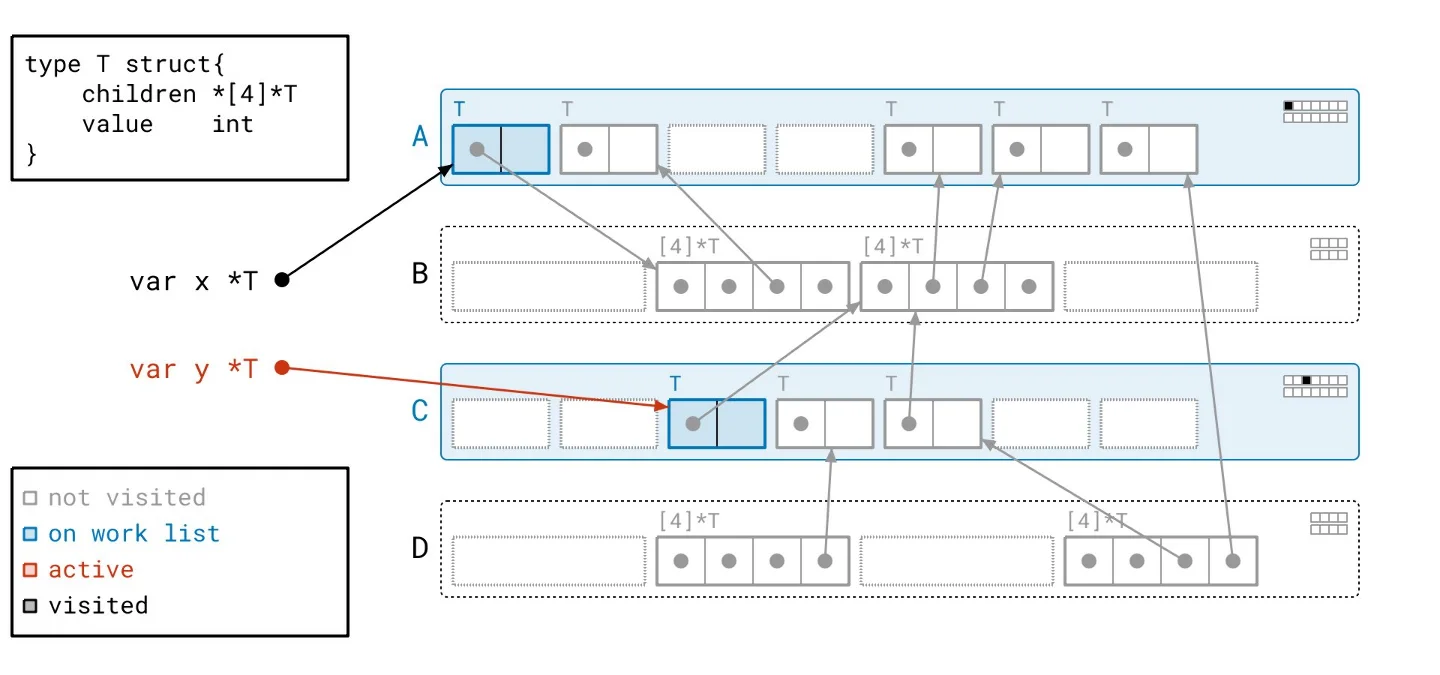
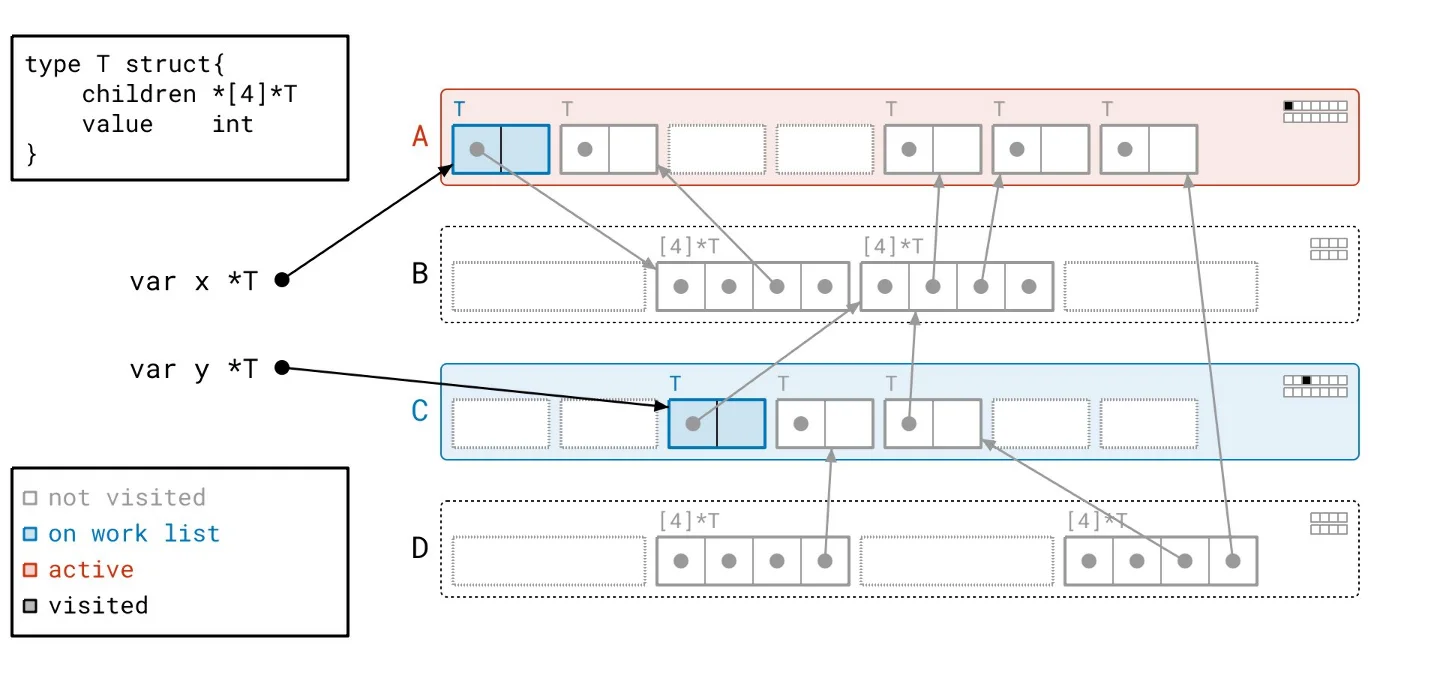
To clarify how this theory translates into practice, we can walk through a series of visual examples that depict this process. Navigate through the accompanying slideshow for a clear breakdown.
The Problem with Current Practices
Having unpacked the mark-sweep algorithm, you might wonder about its drawbacks. The current method works reasonably well but issues arise due to the significant time invested in running this collection process in various applications, often consuming over 20% of CPU time just for garbage collection. Even if the algorithm functions properly, its overhead can hinder overall application performance.
Costs Associated with Garbage Collection
At a fundamental level, the costs tied to garbage collection boil down to two factors: the frequency of its execution and the work done during each cycle. The total load on the garbage collector can be derived from multiplying these two aspects together.
Over the years, efforts have been made to refine both metrics of this equation. While lurking through CPU profiles, we discovered two crucial insights into Go’s garbage collector.
First, approximately 90% of garbage collection's cost arises from the marking process, with a meager 10% linked to sweeping. Optimizing sweeping has always been achievable, thanks to an efficient processor managing memory reclamation for some time now.
Second, of the time spent on marking, a notable fraction—often around 35%—is simply lost due to memory access stalls. This inefficiency severely disrupts the fluid performance characteristic of modern CPUs.
A Microarchitectural Disaster
What does it mean for a process to “gum up the works”? The intricacies of modern CPU architecture can seem daunting, but they are essential to understanding the larger implications of garbage collection issues. Let’s explore this in greater depth...
Traffic Jam for CPUs
Picture the CPU navigating through a complex roadway while executing a program. To accelerate, it needs visibility of the road ahead and a clear path to maintain high speed. Enter the graph flood algorithm, which transforms this journey into a series of stop-and-go scenarios reminiscent of city driving—with countless intersections and obstructions impeding progress. The CPU operates at a disadvantage, forced to frequently decelerate for turns, halt at signals, and dodge pedestrians. The potential speed of the CPU becomes irrelevant if it can't sustain momentum on this convoluted course. To illustrate this further, consider an example where we've outlined our path over the heap. Each horizontal line conveys a segment of scanning performed, depicted alongside the fragmented movement as dashed arrows that represent our constant navigation back and forth between scanning tasks.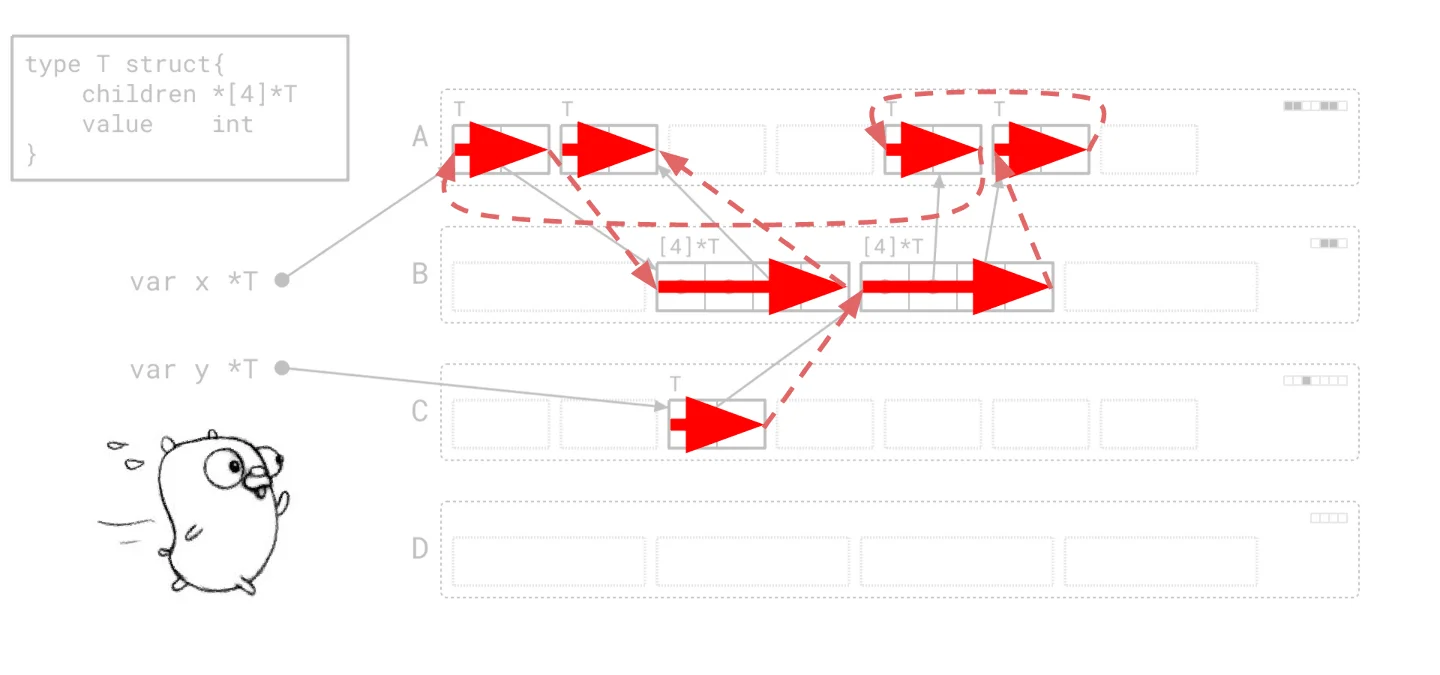
Emerging Challenges
Three primary trends negatively affect garbage collection performance: **Non-uniform Memory Access (NUMA):** Memory access latency is now dependent on the CPU core making the request, leading to uneven performance. This non-uniformity complicates caching strategies since memory locality varies by core. **Diminished Memory Bandwidth:** The bandwidth available per CPU core has been trending downwards. Consequently, while we have more cores processing requests, each core can handle fewer requests at once, exacerbating wait times for data needed from the main memory. **Increasing Core Counts:** Although parallelizing the mark-sweep process initially seems advantageous, it can create bottlenecks. The shared queue of objects that need scanning becomes a limitation as more cores contend for access. Lastly, new CPU features, particularly vector instructions, promise efficiency gains but applying them to the irregular workload of marking objects poses its own challenges. It turns out that achieving efficiency with these heterogeneous tasks isn’t straightforward.Introducing Green Tea
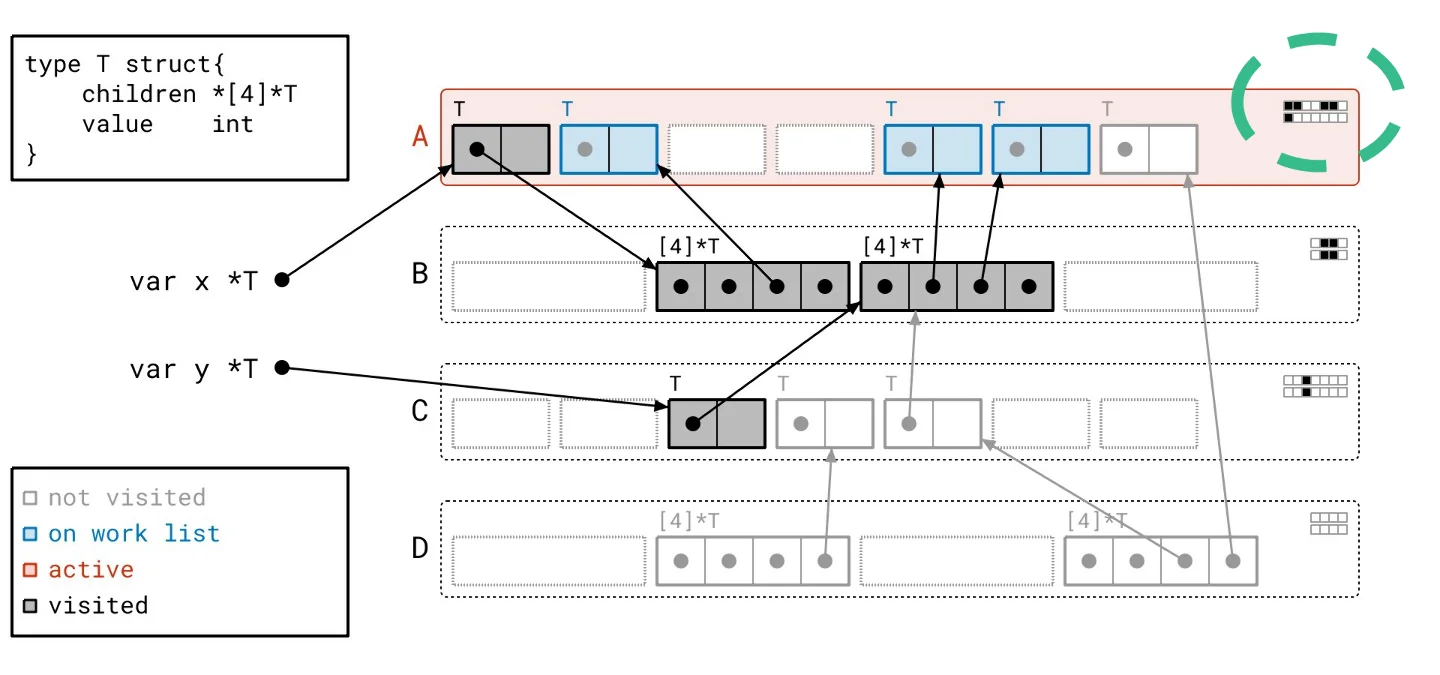
This backdrop sets the stage for our solution, dubbed Green Tea. The underlying principle is refreshingly straightforward: instead of focusing on individual objects, we’ll work with entire pages. What sounds like a trivial pivot is anything but. Developing a method to effectively orchestrate how we walk through the object graph and manage tracking took extensive effort. To put it concretely: - We scan whole pages rather than individual objects. - Our work list now contains entire pages, not just single objects. - Final marking of objects still occurs but is managed locally within each page rather than across the entire heap.Green Tea in Action
Let’s revisit our heap, applying the Green Tea methodology instead of the traditional graph flood. As we navigate through the updated illustrated slideshow, we can observe tangible differences in how we process the heap. It’s crucial to highlight the more organized workflow facilitated by Green Tea. The process allows us to handle multiple related objects at once, significantly reducing the number of separate scans needed compared to the graph flood method.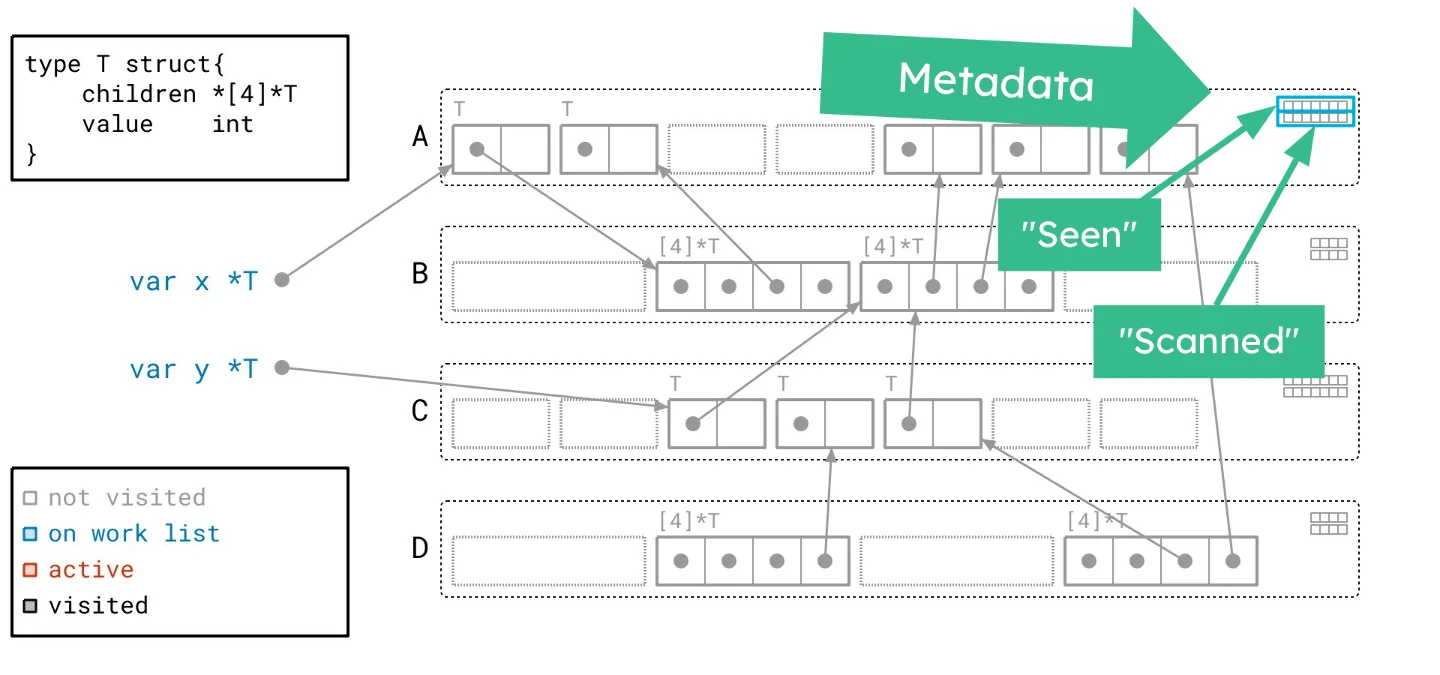
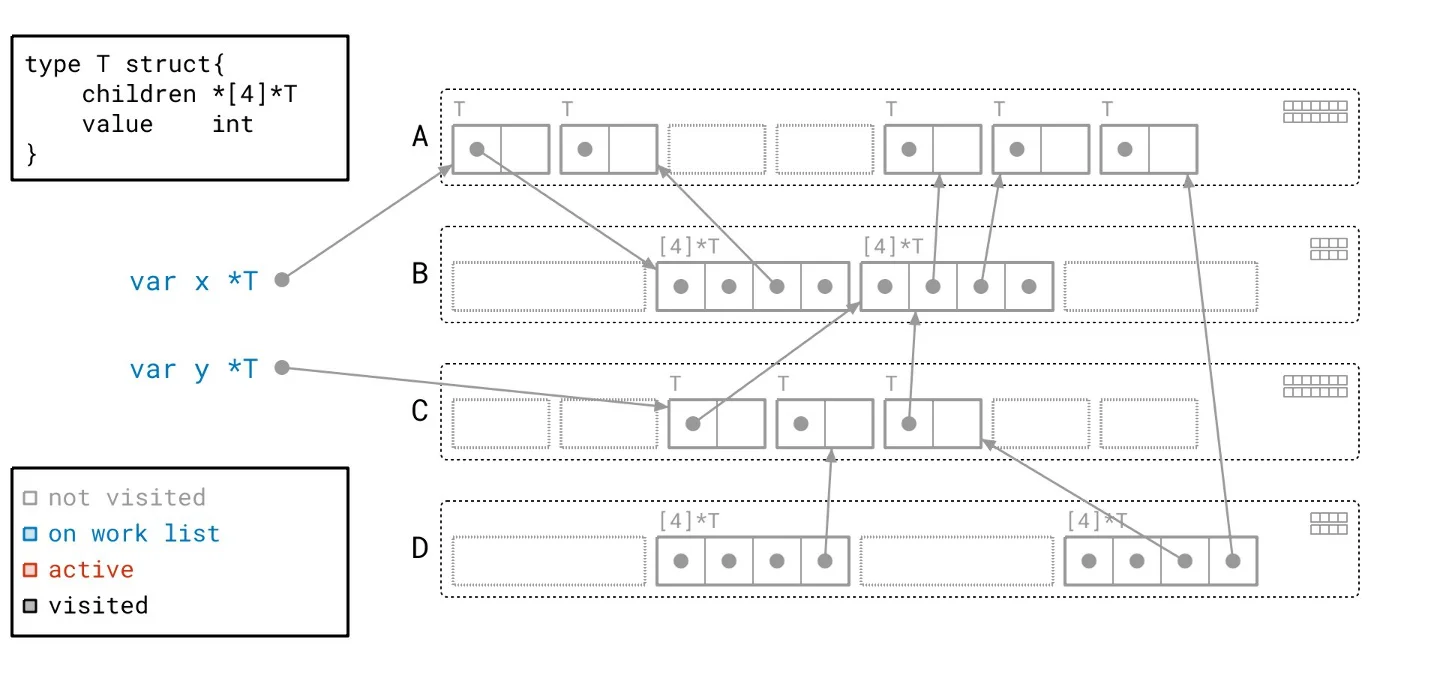
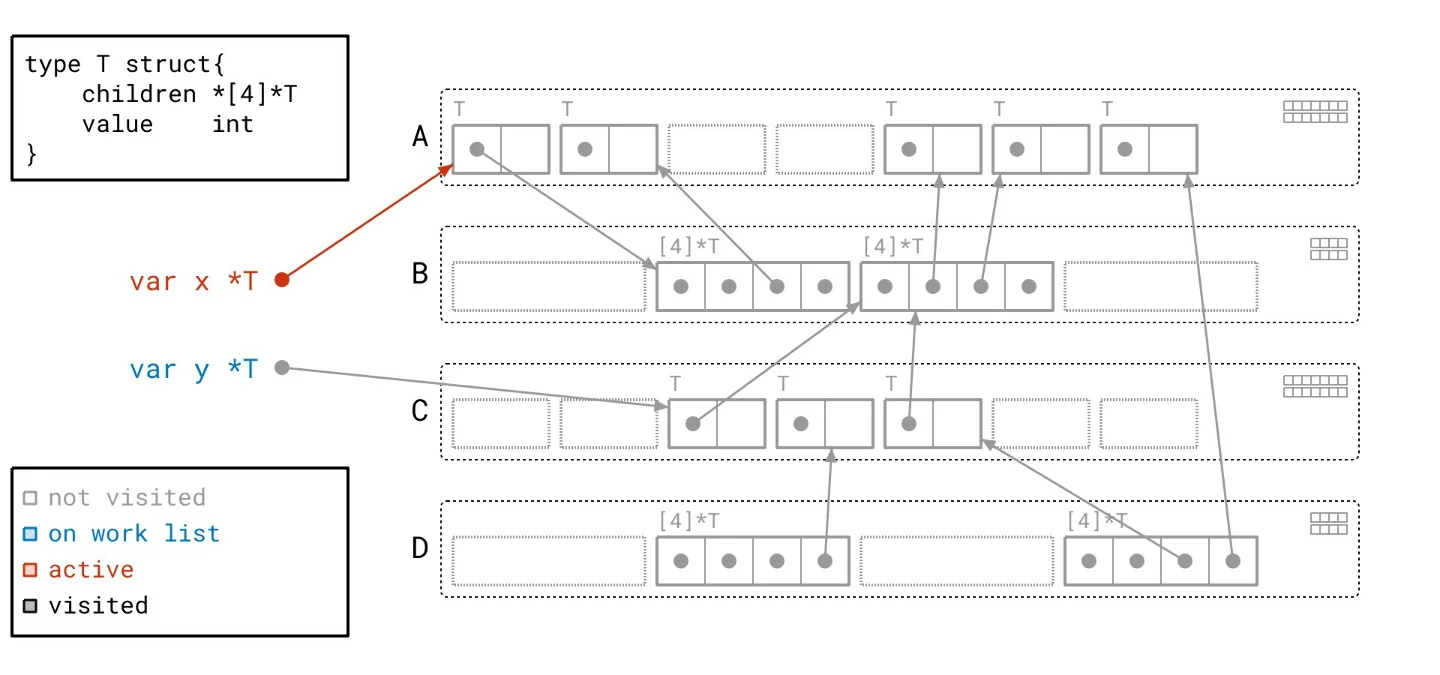
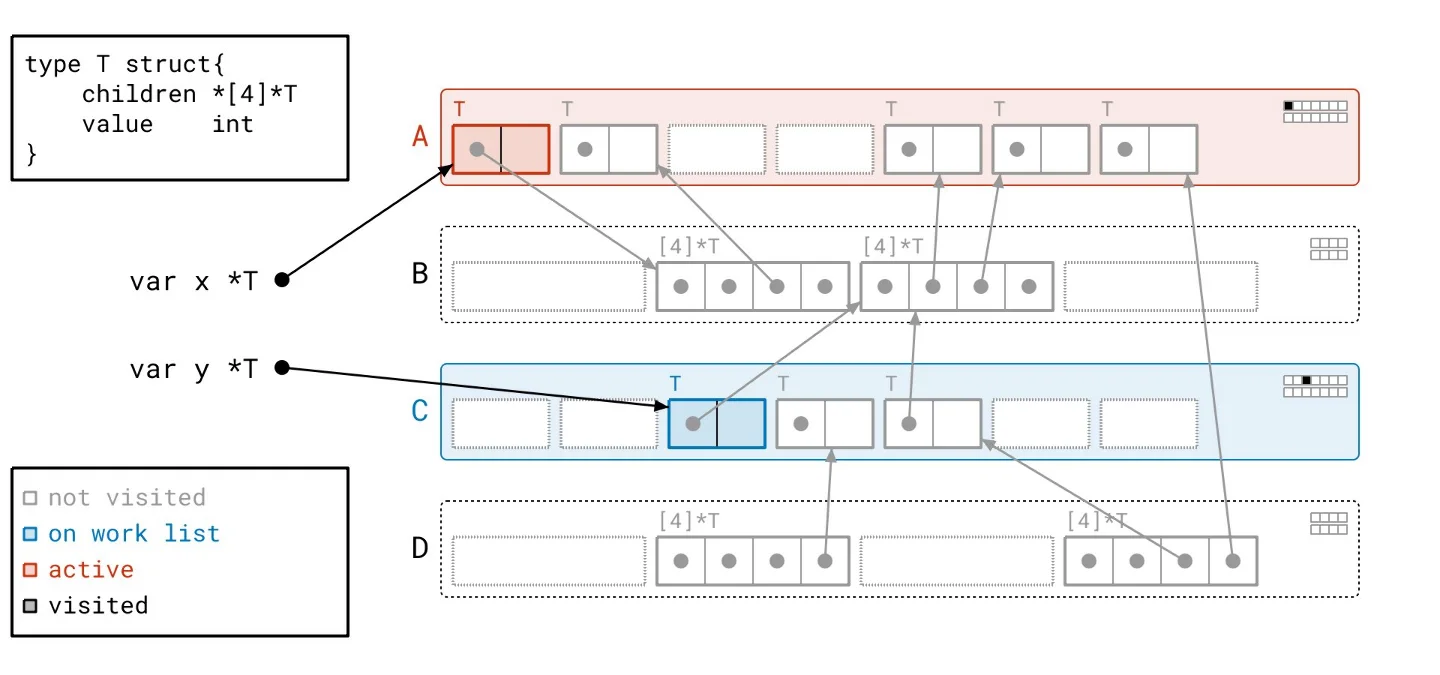
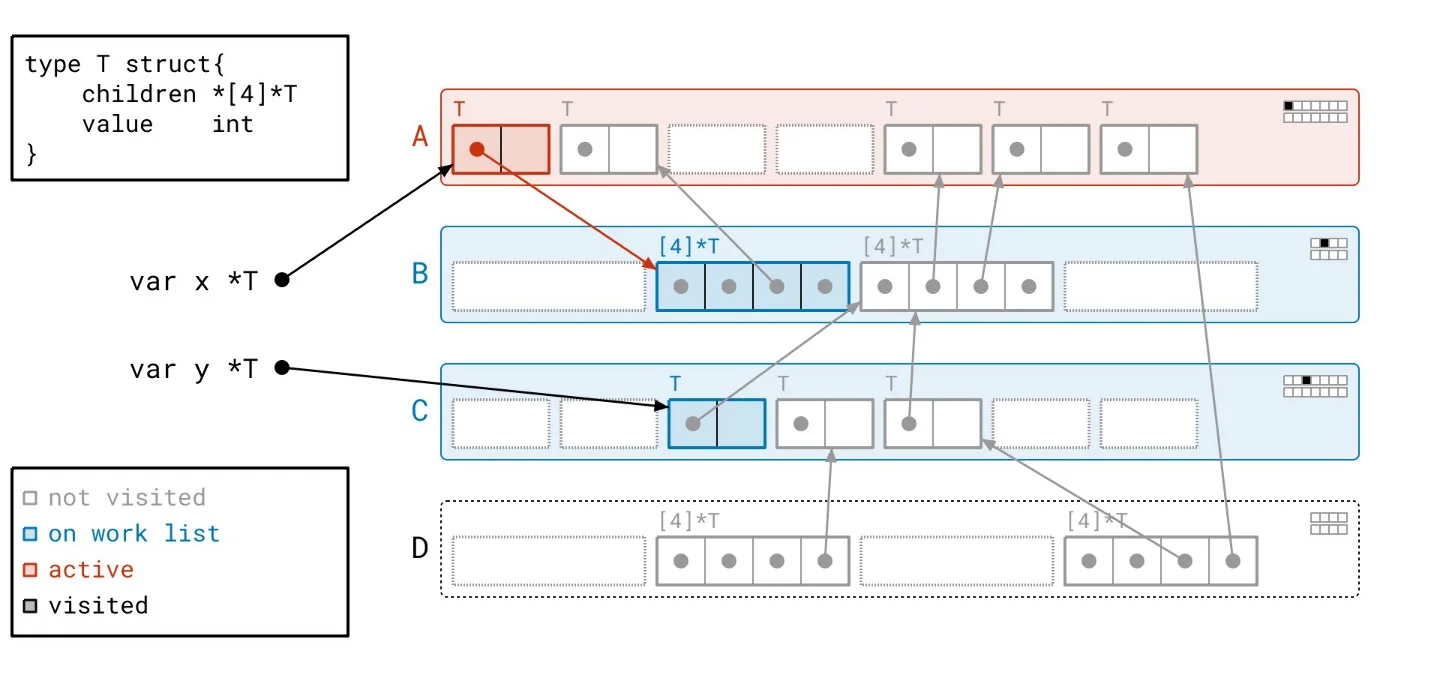
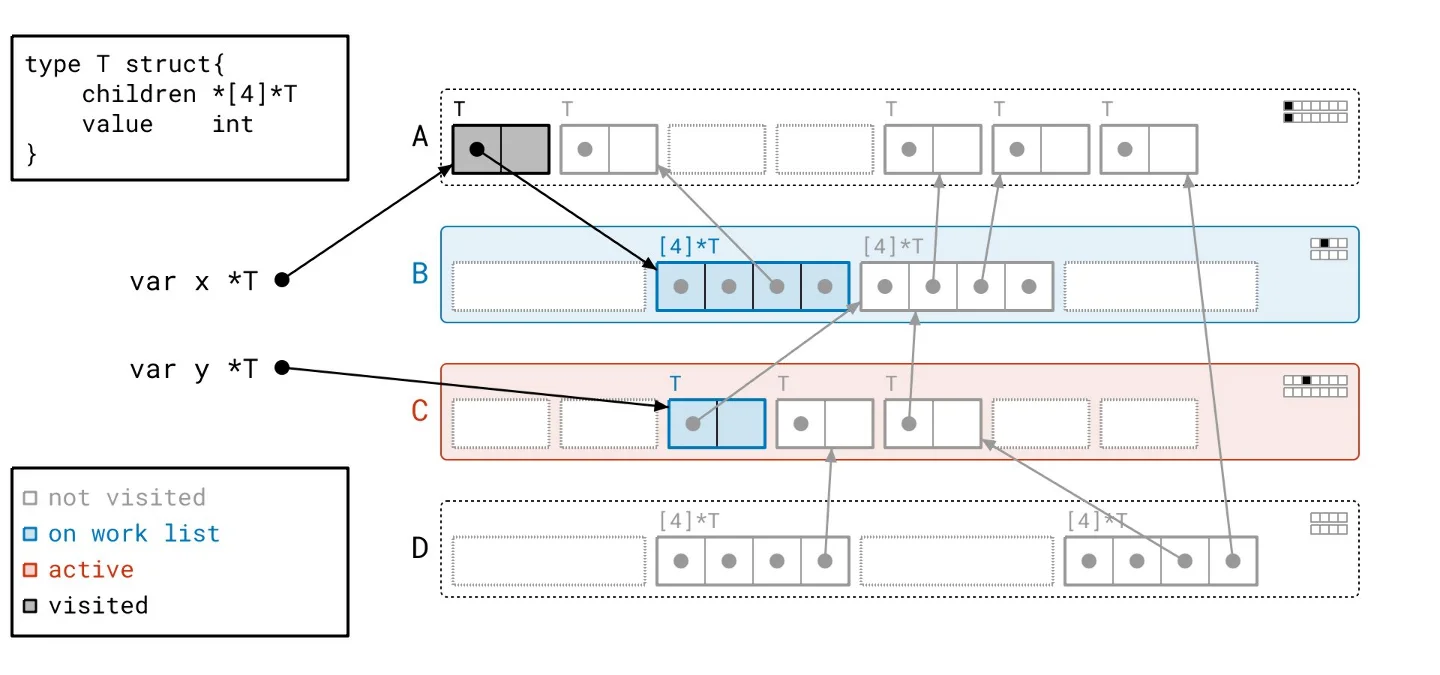
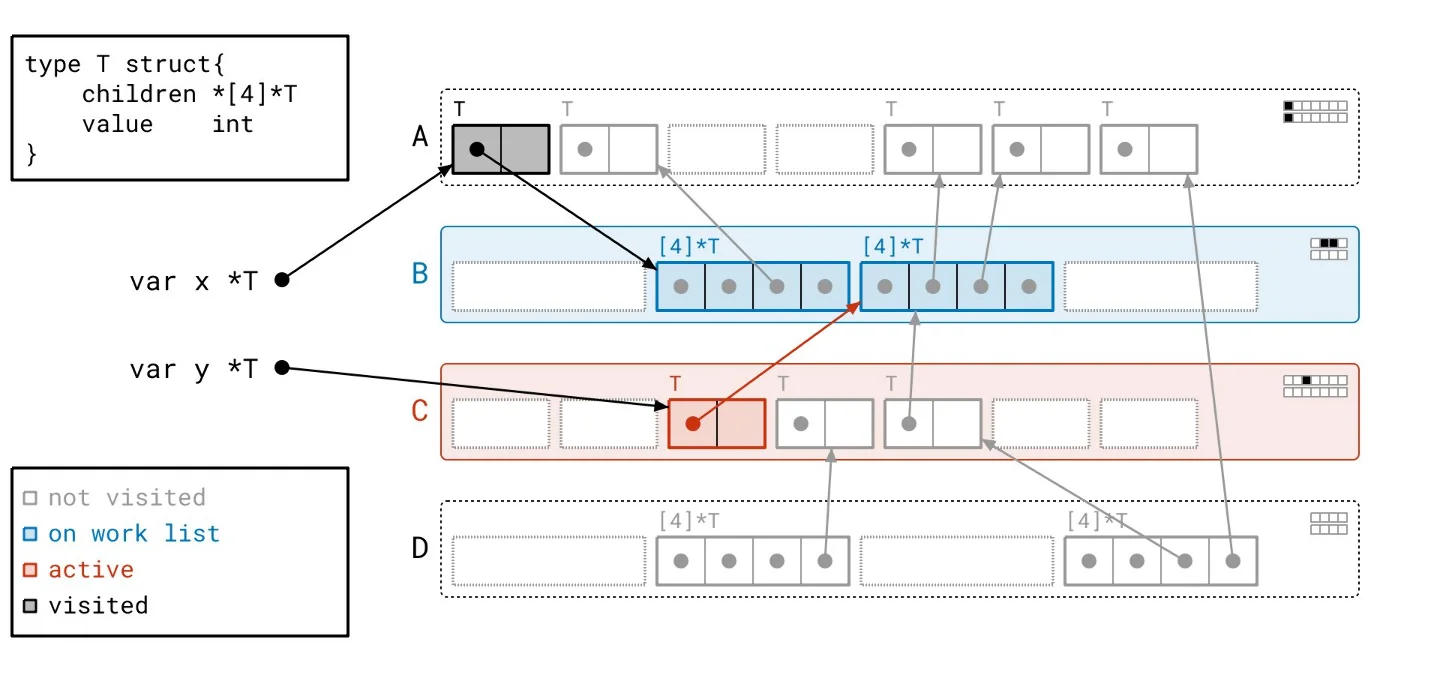
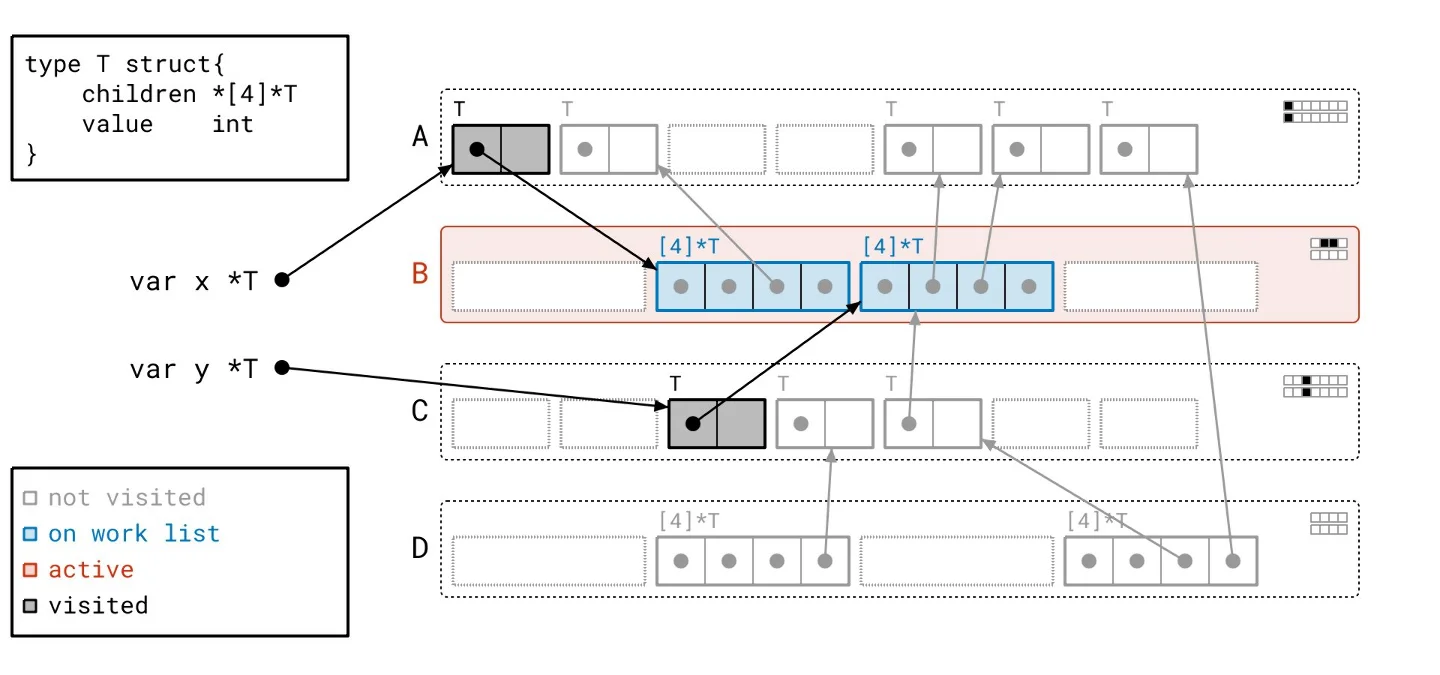
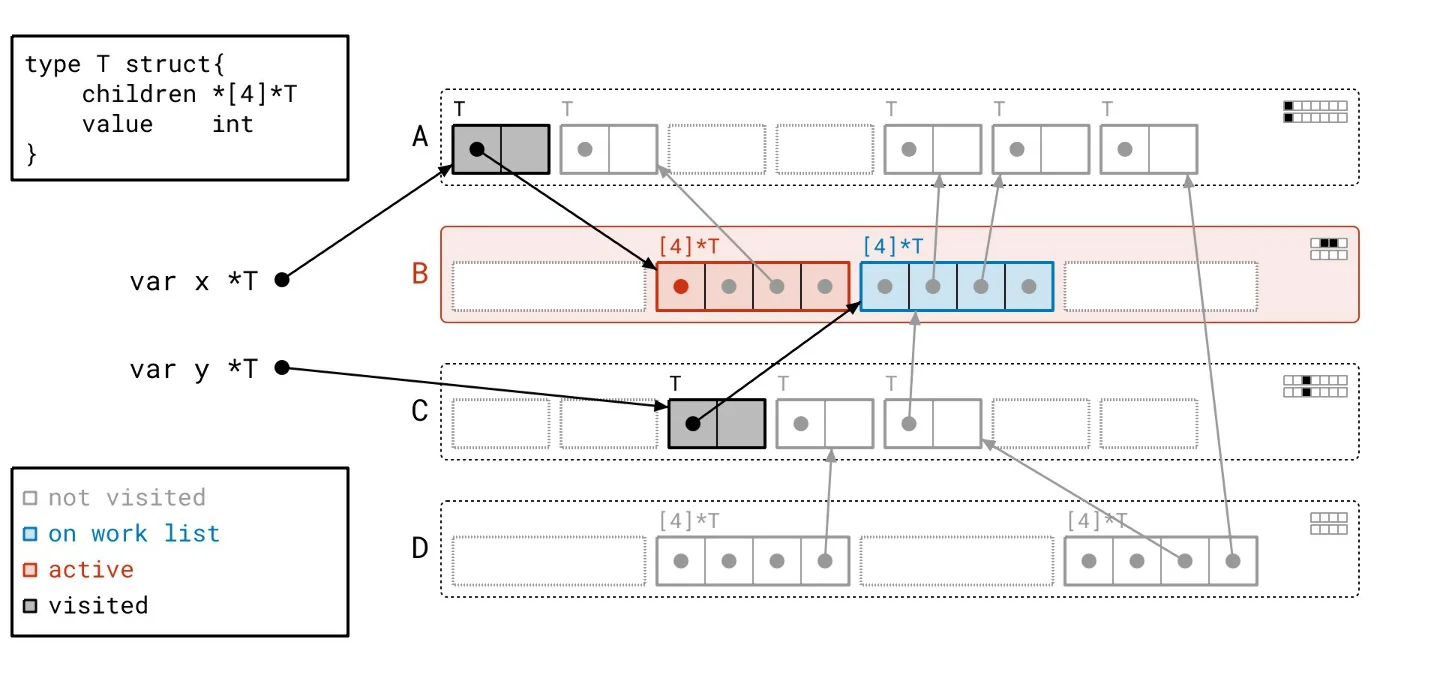
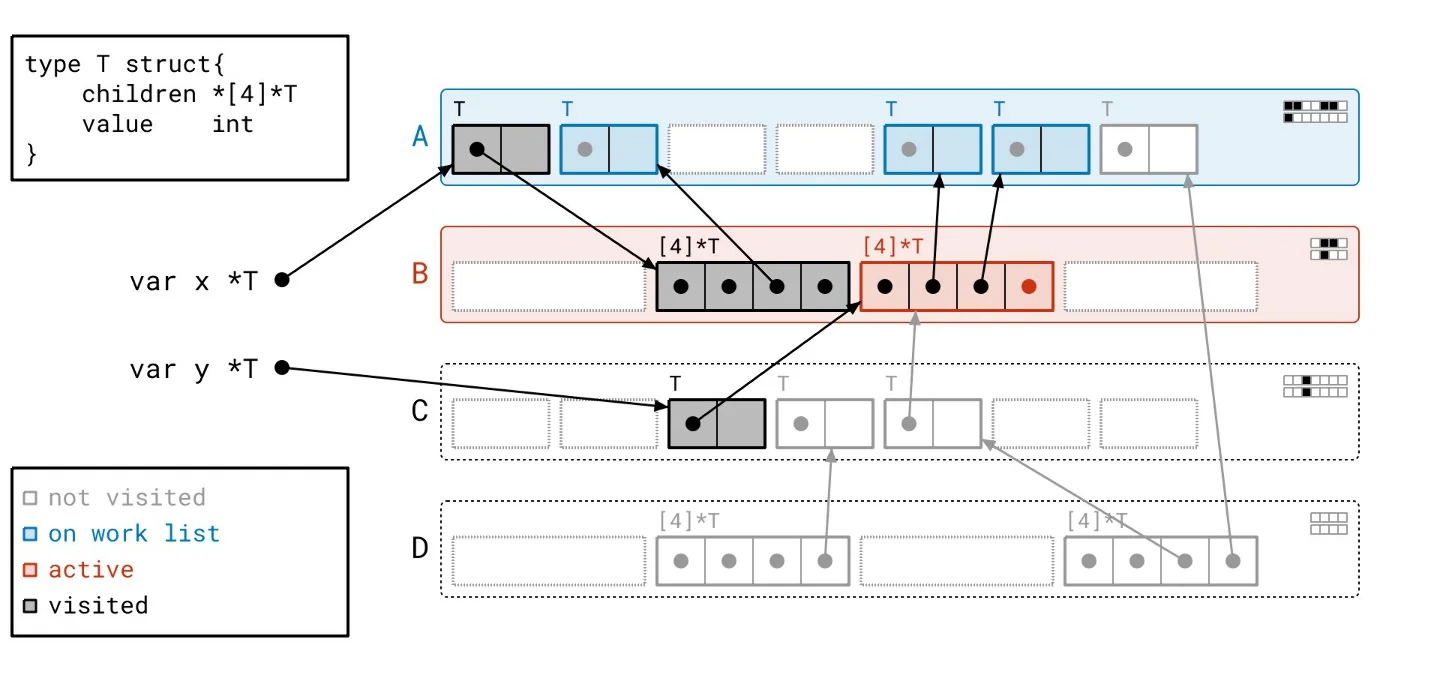
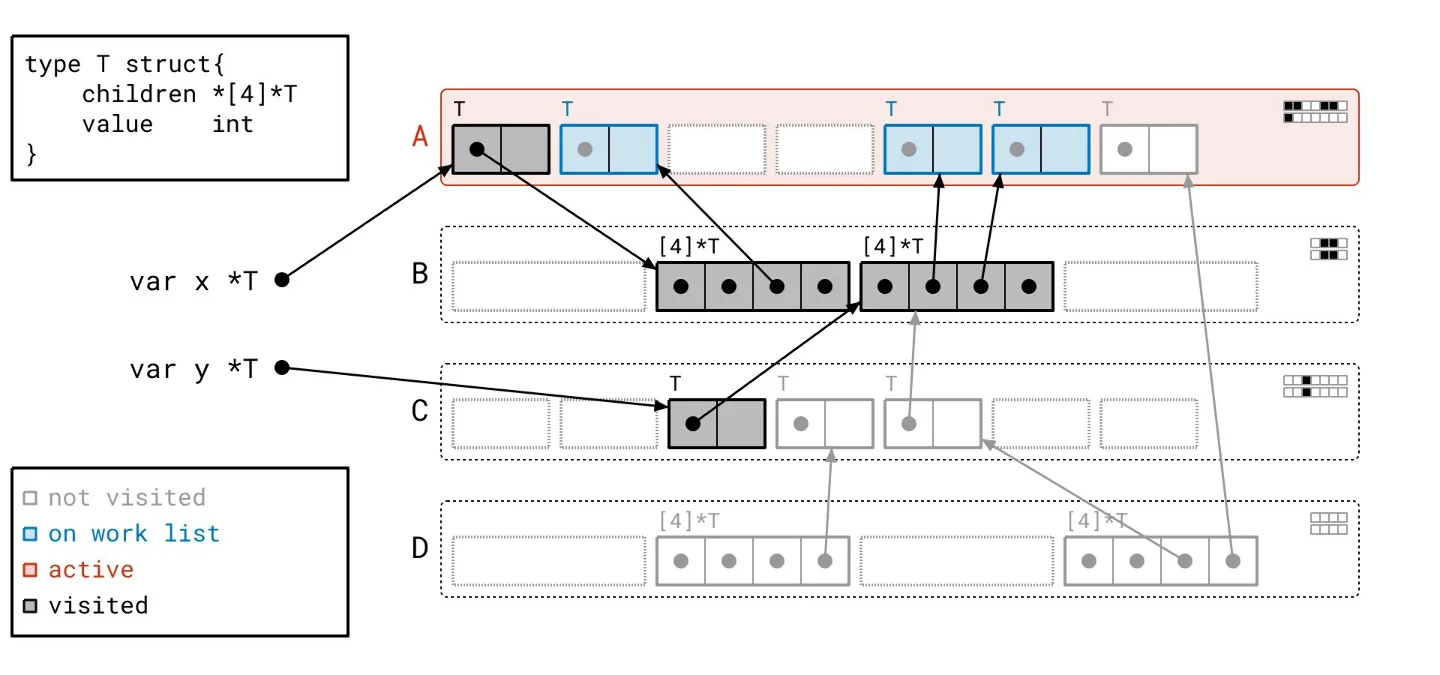
Harnessing Vector Hardware
If you’re not well-versed in vector computing, the connections to Green Tea might initially seem obscure. However, beyond performing conventional arithmetic operations, modern vector architectures empower two crucial capabilities: expansive registers and advanced bit-level operations. With most contemporary x86 processors integrating AVX-512 capabilities, the technology boasts 512-bit vector registers. This width enables the entirety of a page’s metadata to fit within just two registers, allowing Green Tea to manipulate this entire page with a lightweight execution of instructions. Moreover, from advancements like AMD Zen 4 and Intel Ice Lake, a new bitwise operation has emerged that streamlines part of the Green Tea scanning sequence to mere CPU cycles, enhancing processing speed. Historically, employing vector hardware would prove inefficient with the graph flood method due to its fragmented memory accesses and wildly varying object sizes, which would render predictable processing infeasible. For those wanting a deep dive into the mechanics behind these processes, I invite you to read on. If that’s not your speed, feel free to jump ahead to the evaluation.Vision of the Future with AVX-512
To grasp how the AVX-512 garbage collection scanning operates, observe the diagram below.
0 0 1 1 ...→
000000 000000 111111 111111 ...
-
4. Next, we retrieve the pointer/scalar bitmap for the page, dictating which words safeguard pointers.
5. Then, we proceed to derive the “active pointer bitmap”—pinpointing where the live objects we haven’t scanned reside.
6. Lastly, instead of handling one object at a time, the iteration allows us to collect pointers in batches, efficiently processing the entire page in mere handful of instructions thanks to vector capabilities.
Looking Ahead: The Promise of Green Tea
As we conclude our exploration of Green Tea, it's essential to recognize not just the technology itself but the collaborative journey that got us there. At first glance, this new garbage collection method might appear as a singular achievement, yet it's a rich tapestry woven from the collective insights and contributions of many dedicated individuals over several years. The introduction of theVGF2P8AFFINEQB instruction offers a remarkable efficiency boost in the scanning kernel by enabling complex bit manipulations at high speed. This isn't merely a technical upgrade; it fundamentally changes how we think about memory management in Go. The Galois field mathematics that underpins these operations allow us to define custom bit matrices efficiently, achieving significant reductions in CPU usage. With gains of up to 40% in some benchmarks, the impact could be widespread for applications with regular memory structures.
However, this evolution isn't without its challenges. While many workloads have benefited from the introduction of Green Tea, certain others remain less accommodative, particularly those that necessitate scanning only a single object at a time. This can lead to suboptimal performance, raising valid concerns about the underlying assumptions of how objects are structured in memory. Yet, even with those complexities, the ability to outperform traditional methods with merely 2% of a page scanned is a testament to the innovation at play here.
The work doesn't stop with the initial rollout. Future iterations, including vector enhancements anticipated for Go 1.26, are poised to refine the process further. As feedback continues to roll in from users experimenting with Green Tea, we can expect ongoing adjustments that will only fortify its robustness.
Looking to the future, the evolution of Green Tea represents a significant leap not just in garbage collection but in the very framework of Go's performance. This is truly a testament to the power of collaboration, experimentation, and the willingness to iterate. If you're involved in this space, keep a keen eye on how these developments unfold. The path ahead looks promising, and we invite you to participate in shaping it by providing valuable feedback on your experiences.
In summary, Green Tea isn’t just a technical upgrade; it’s a living example of how a community effort can lead to substantial advancements. The encouragement to explore this feature, even in its experimental phase, underscores the innovation mindset at play within the Go community. If you haven’t tried it yet, do set GOEXPERIMENT=greenteagc and provide your insights. We're excited about the journey ahead and eager to see where this leads us!